











Morningstar’s analysts can cover a limited number of funds, “those investments that are most relevant to investors and that hold a significant portion of industry assets.” When analysts cover a fund, they issue a forward-looking rating based on five research-driven “pillars.” Those ratings are described by medal assignments: Gold, Silver, Bronze, Neutral and Negative. The analyst ratings are distinct from the iconic star ratings; the star ratings are backward looking (they tell you how a fund did based on risk and return measures) while the analyst ratings are forward-looking (they aspire to tell you how a fund will do based on a broader set of factors).
 As a practical matter, few smaller, newer, independent funds qualify. In response to concerns from clients who believe that Morningstar’s assessment is an important part of their compliance and due-diligence efforts for every fund they consider, Morningstar has unveiled a second tier of ratings. These ratings are driven by a machine-learning algorithm that has been studying two sets of data: the last five years’ worth of analyst ratings and the ocean of data Morningstar has on the components and metrics of fund performance. The goal was to produce ratings for all “analogous to” those produced by Morningstar analysts. Like the analyst ratings, they would could in Gold/Silver/Bronze and so on. Unlike the analyst ratings, they would be based purely on quantitative inputs (so the observation “he’s an utter sleazeball and a lying sack of poop” might influence the analyst’s judgment but would be unavailable to the machine). Here are the methodological details.
As a practical matter, few smaller, newer, independent funds qualify. In response to concerns from clients who believe that Morningstar’s assessment is an important part of their compliance and due-diligence efforts for every fund they consider, Morningstar has unveiled a second tier of ratings. These ratings are driven by a machine-learning algorithm that has been studying two sets of data: the last five years’ worth of analyst ratings and the ocean of data Morningstar has on the components and metrics of fund performance. The goal was to produce ratings for all “analogous to” those produced by Morningstar analysts. Like the analyst ratings, they would could in Gold/Silver/Bronze and so on. Unlike the analyst ratings, they would be based purely on quantitative inputs (so the observation “he’s an utter sleazeball and a lying sack of poop” might influence the analyst’s judgment but would be unavailable to the machine). Here are the methodological details.
On March 28, 2018, I had to chance to speak with Jeff Ptak and Tim Strauts about the system and its implications. Jeff is Morningstar’s global director of manager research, Tim is their director of quantitative research and one of the brains behind the new system. We played around with three topics.
Is the machine good?
Performance in the back tests, they aver, “is pretty good.” The rough translation is that the machine has roughly the same level of predictive ability as do the human analysts.
Does the machine get to replace the humans?
Of course not. (If I had a nickel for …) The machine and the humans do not always agree, in part because they’re focused on slightly different sets of inputs. The humans factor conversations into their judgment of the “People” pillar, for instance, while the machine factors in Sharpe ratio as part of “People.” For now the machine and the humans agree on the exact rating about 80% of the time; it could be higher, but Tim argues that he didn’t want to “overfit” the model. The more important point, in their minds, is that they’re largely avoided “the very bad problem” that would result if the machine issued a “negative” rating on the same fund where the analysts assigned a positive one. That occurs in “much less” than 1% of the ratings.
Beyond that, the machine learns from the analysts’ rating decisions. They need to keep making new decisions in order for it to become more sophisticated.
Is there a way to see the machine’s outputs? That is, can we quickly find where the machine found bits of gold or silver that the analysts missed?
Nope. Jeff and Tim are going to check with the Product team and the Prospects team, but they neither knew of any particular cool finds made by the machine nor of any way for outsiders to search the ratings just now.
The ratings are available, fund by fund, on Morningstar’s new (low profile) fund pages. When you pull up a fund’s profile, you see a simple link to the alternate profile page.

If you click on the link in the colored bar, you see
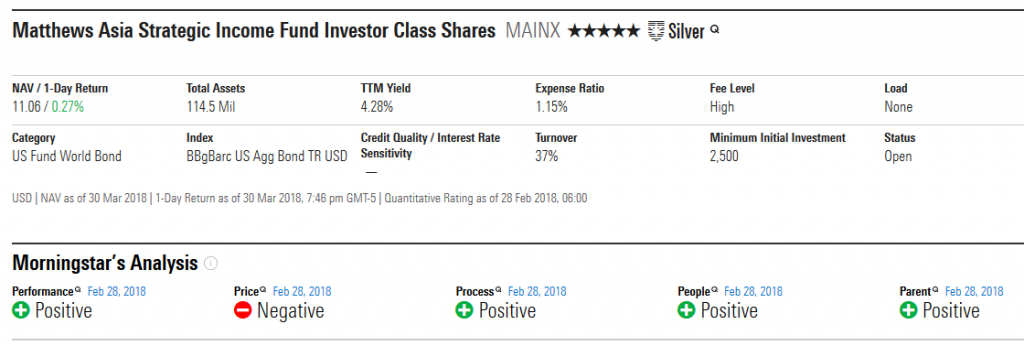
Out of curiosity, I ran a screen for all five-star domestic equity funds with under $1 billion in assets, then clicked through each profile. About half of the funds have a neutral rating and just two have negative ratings. Excluding a few funds available just through insurance products, here’s the list of “non-neutral” funds with the links to their MFO profiles when available. Many of these are purely institutional funds or the institutional share classes of funds, which reflects the effect of expenses on a fund’s ratings.
Update: Jeffrey Ptak updates us via Twitter
Gold
Glenmede Total Market Portfolio GTTMX
Silver
Fuller & Thaler Behavioral Small-Cap Equity FTHFX – an MFO “Great Owl” fund. Great Owls, a term derived from the Great Horned Owl which inspired MFO’s logo, are fund’s that are in the top 20% of their peer group, based on risk-adjusted returns, for every trailing measurement period.
Hartford Schroders US Small/Mid-Cap Opportunities Fund Class I SMDIX – “Great Owl”
Jackson Square SMID-Cap Growth Fund IS Class DCGTX – “Great Owl”
Johnson Enhanced Return Fund JENHX – “Great Owl”
Lord Abbett Micro Cap Growth Fund Class I LMIYX
Nationwide Small Company Growth Fund Institutional Service Class NWSIX – “Great Owl”
Nationwide Ziegler NYSE Arca Tech 100 Index Fund Class A NWJCX
Shelton Capital Management Nasdaq-100 Index Fund Direct Shares NASDX
Tributary Small Company Fund Institutional Class FOSCX – “Great Owl”
Victory RS Small Cap Equity Fund Class A GPSCX
William Blair Small Cap Growth Fund Class I WBSIX
Bronze
AT Disciplined Equity Fund Institutional Class AWEIX
Conestoga SMip Cap CCSMX
Glenmede Strategic Equity GTCEX
Government Street Mid-Cap Fund GVMCX – “Great Owl”
Manning & Napier Disciplined Value Series Class I MNDFX
Morgan Stanley Institutional Fund, Inc. Advantage Portfolio Class I MPAIX
Morgan Stanley Institutional Fund, Inc. Insight Portfolio Class I
Pin Oak Equity Fund POGSX
T. Rowe Price Capital Opportunity Fund PRCOX
T. Rowe Price Institutional U.S. Structured Research Fund TRISX
Negative
Catalyst Buyback Strategy Fund BUYIX – negative on parent, price, and people
Salient US Dividend Signal Fund Institutional Class FDYTX – negative on price, process and people